The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreloadAbstract
We aim to study the history and effects of incorporation in Russia. Our project uses historical primary data from Russian factory censuses which were digitized, cleand and curated by Professor Amanda Gregg and are freely available on the American Economic Association’s website. While economic historians frequently bicker about the origins and effectiveness of corporations- most agree that the 19th century witnessed the rise of the corporate business form in Europe and North America. Firms in Russia began incorporatinng relatively late- in the late 19th century. We aim to study the factors that may lead to a firm choosing to incorporate- and to study the effects of incorporation on the firm itself. We intend to use supervised learning and feature engineering to study the variables that are the most influenced incorporation, and the variables that make incorporation more likely. We need to note that this is an unbalanced data set, in the sense that most factories are not incorporated.
We have used this replication data set to test our machine learning models (logistic regression, etc) and make predictions. We looked out for bias in machine learning, since our data set is unbalanced. Also, it is a historical fact that there was only a low percentage of incorporation going on in Late Imperial Russia at that time. Our data comes from (here)[https://www.aeaweb.org/articles?id=10.1257/aer.20151656], and our question is how to predict whether a factory incorporate or not in that period. Our model should be about to give predictions that are more or less consistent with the arguments presented in the published paper, “Factory Productivity and the Concession System of Incorporation in Late Imperial Russia, 1894-1908.” We focused on using supervised learning to look at how different features relate to the dependent variable, which is incorporated or not. Our main result is using logistic regression to predict if factories would incorporate or not, and our model is quite useful and agrees with our economics intuition.
The source code for this project could be found here. We have a README.md file that outlines what our project want to achieve, and roughly how we are going to implement the models and analysis. We also have a separate .txt file that gives a dictionary of all the variable names and their actual meaning. Hence, we encourage the reader to also reference that .txt file to remember what does each variable represent.
Introduction
What is incorporation? Why does it matter?
Incorporation is the process by which a firm becomes a corporation. A corporation is a firm that is recognized as a separate legal entity independent of its owners. As it is a state’s decision to recognize a corporation as an entity that is a separate legal being, incorporation is a privilege granted by a state.
According to economic historian Ron Harris, a corporation exhibits four key features.
Transferrable shares: This signifies that the ownership of a corporation can be split into multiple shares. These shares can be raised, bought and sold freely. When a corporation is allowed to sell shares, it can raise capital at a rapid rate for projects that it wishes to partake in. However, by selling shares in its corporation, the original owners may risk losing control as any entity with a majority stake in the corporation can make executive decisions.
Separate legal personhood: In a legal sense, a corporation has a legal personality that is separate from its owners. This means that a corporation can legally perform various tasks a person can, such as owning property, entering into contracts and suing and being sued by other parties. It also means that the death of an owner, or a sudden change in ownership or control of the firm has no effect on its continued legal existence. It also means that corporations can be held accountable for its actions, irrespective of who owns or controls it.
Limited liability: limited liability can be viewed as an extension of the idea of separate legal personhood. This implies that an owner cannot be liable for more money than what they invested into the corportion. Hence, if a corporation has one owner who decides to invest 100 dollars, and corporation needs to pay 1000 dollars in fines while facing bankruptcy, the owner cannot be held liable for more than what they invested. The rest of the debt belongs to the corporation
Separation between the ownership and management of the firm: Fractional ownership of the firm allows for a specialized management independent of the majority ownership of the firm to emerge. This allows for managers that can be hired and fired based on merit.
Economists and legal scholars frequently debate about the effectiveness of corporations. Incorporation comes with several advantages and disadvantages. The advantages of incorporation- such as being able to raise capital rapidly due to transferrable shares and having relative stability due to its separate legal personhood- are easy to observe. Society at large could also benefit from firms sharing However, it can also have several disadvantages for its owners and society at large. The owners of a corporation can be forced out of control by a hostile takeover if another entity owns more than 50% of the issued shares. Corporations could also abuse the rights given to it by the state to engage in malpractice that harms workers and causes economic crises.
Some historical context about Russia and descriptions about the Russians system of incorporation
Since the development of corporations in the 16th century, the legal codes allowing them to exist have been adopted by nearly all countries. Most countries, rightly, treated the idea of corporations with both excitement and apprehension. This is certainly true for Imperial Russia in the late 19th century. Russia observed the rapid advancement of Western European states such as England, Holland and Germany as a security threat. It wanted to create a system, with its limited resources, that allows for the existence corporations, while also maintaining a high degree of regulation.
Hence emerged the “Concession System of Incorporation” in Russia. Under this system, incorporation was granted in a slow, tedious and expensive manner on a case-by-case basis. The high costs and logistical challenges posed a serious barrier towards firms wishing to incorporate. Hence, under these circumstances, only some firms would benefit from incorporation, and would choose to incorporate. In this project, we wish to study the characteristics of firms that would choose to incorporate in this context. Doing so can allow us to better understand the economy of early 20th century Russia, the adoption and development of corporations, and the fundamental nature of corporations.
Our work verifies and builds upon Professor Amanda Gregg’s work on corporations in Russia in “Factory Productivity and the Concession System of Incorporation in Late Imperial Russia, 1894–1908”
Data
We get our data from the Imperial Russian Factory Database, 1894-1908, compiled by Professor Gregg. This dataset is a digitzation of the Russian factory censuses from 1894, 1900 and 1908. This data is at the factory level, and includes information about the size of the factory’s workforce, the total power of its equipment, its revenue, and whether the firm owning it incorporated or not. It also contains information about the location of the firm and the date of its incorporation.
We hope to use this data to examine the types of industries that would benefit most from incorporation.
- insert viz+statistics about number of factories belonging to corporations and non-corporations
- insert visualization for number of factories by sector and ownership
- insert visualization for factories by workforce, split by sector and by corporations/ non-corporations
- insert visualization for factories by power used, splot by sector and corporations/ non-corporations
- insert same by revenue
First, let us import some libraries that will become useful down the road. Also, the following snippet will automatically reload the final_project_code.py file where we keep our functions.
Code
from matplotlib import pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from final_project_code import FinalProject
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from itertools import combinations
from matplotlib.patches import Patch
import seaborn as sns
from mlxtend.plotting import plot_decision_regions
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_reportRead in the data
Let us create an instance of the class we defined in final_project_code.py, and let us read in the entire data set.
Let us now observe some summary statistics about our dataset.
The following visualization demonstrates the number of corporations and non-corporations in our dataset:
Code
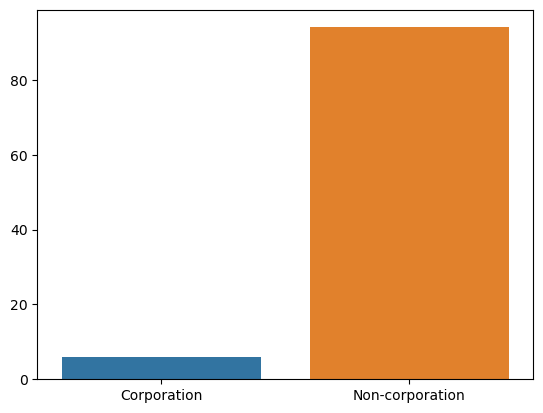
As we can observe, we have significantly more factories owned by non-corporations than we do factories owned by corporations. This has the potential to impact our research methods. We will discuss this further later in the blog post. Let us also break this chart down by the type of industry.
Code
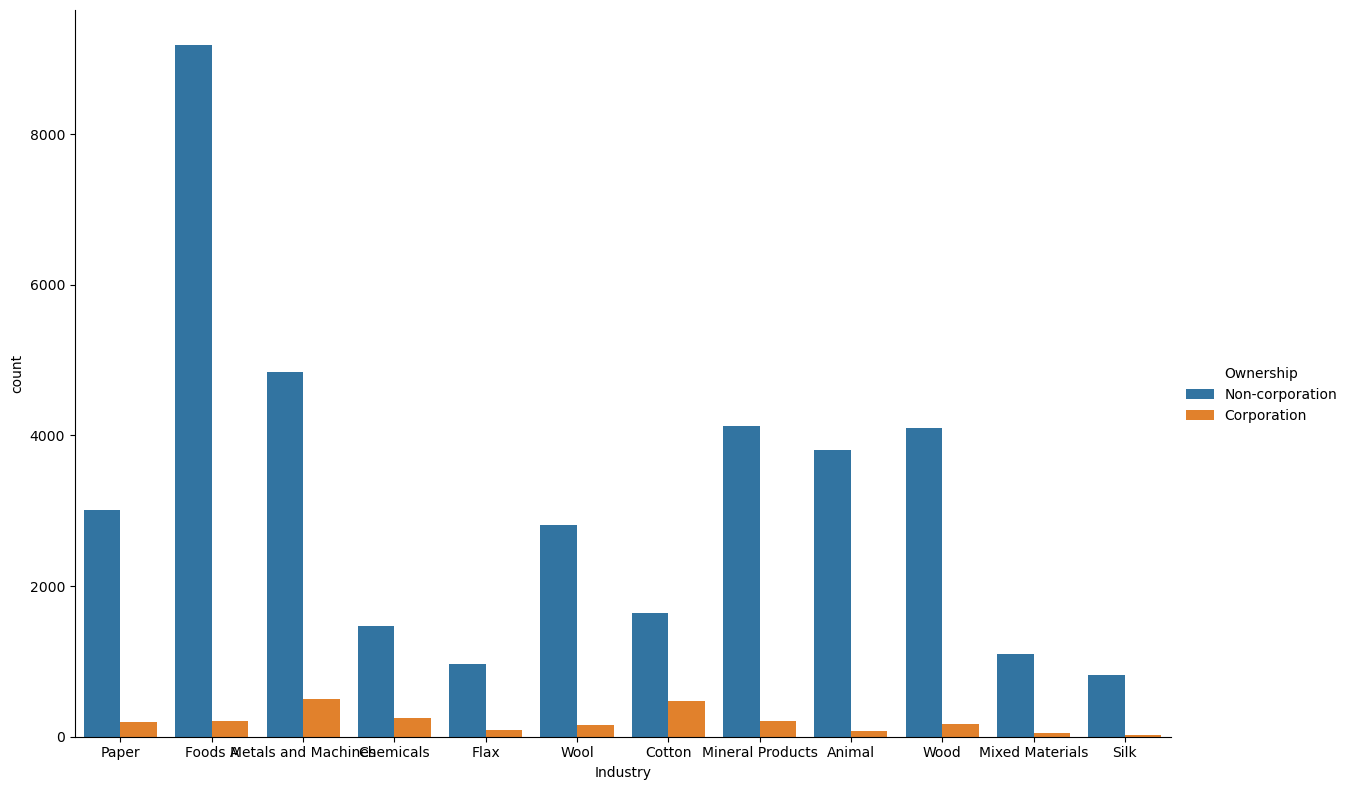
We can already initially observe that certain industries how a high proportion of factories owned by corporations compared to other industries. For example, the metals and machines, cotton and chemical industries have a significantly higher proportion of factories being owned by incorporated firms.
We can also take a look at the number factories in each industry in our dataset. We observe that the food and metals industries have the greatest number of factories, while we have relatively few factories for silk and flax.
Let us now take a look at the number of workers employed at each factory.
Code
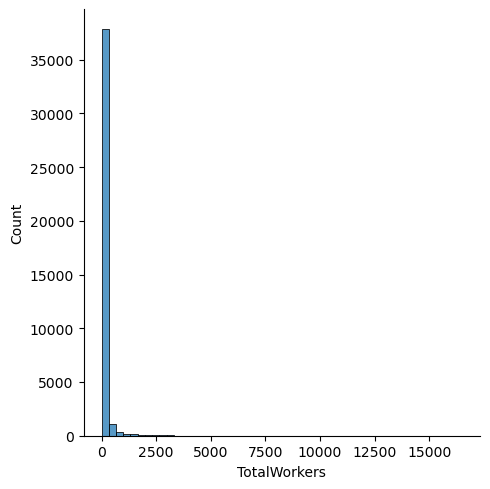
We can see that have a large number of factories with very few workers, and very few factories with a large number of workers.
Let us now compare this distribution with the distribution for only corporation-owned factories:
Code
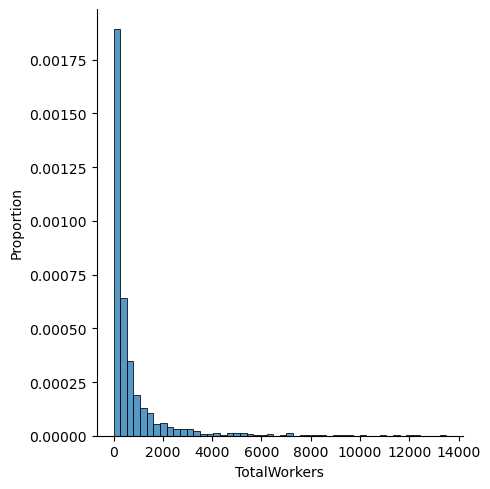
As we can see, while observe a similar trend for corporation owned factories- this distribution has a fatter tail- indicating that factories owned by corporations have more workers. Let us perform the same analysis for total power per factory:
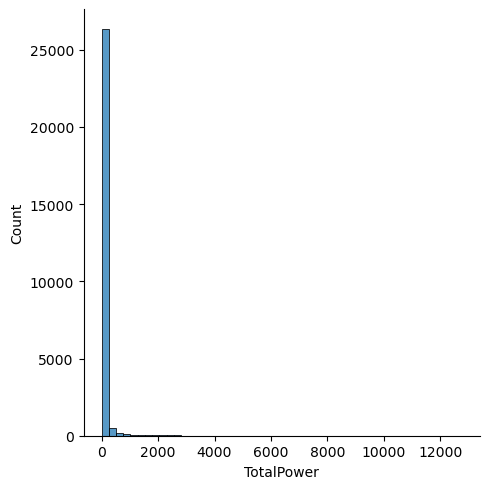
Code
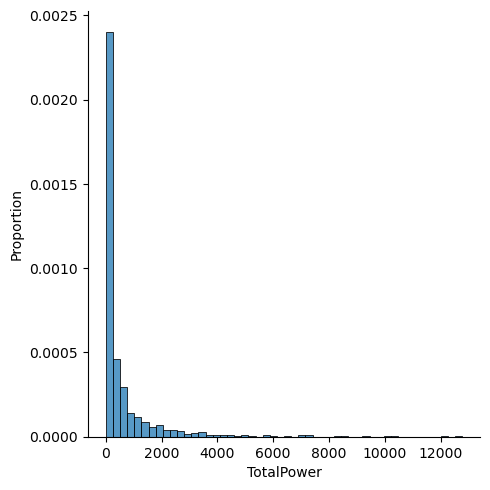
We can draw similar inferences from our distribution for power: factories owned by corporations are more likely to employ a greater total power value.
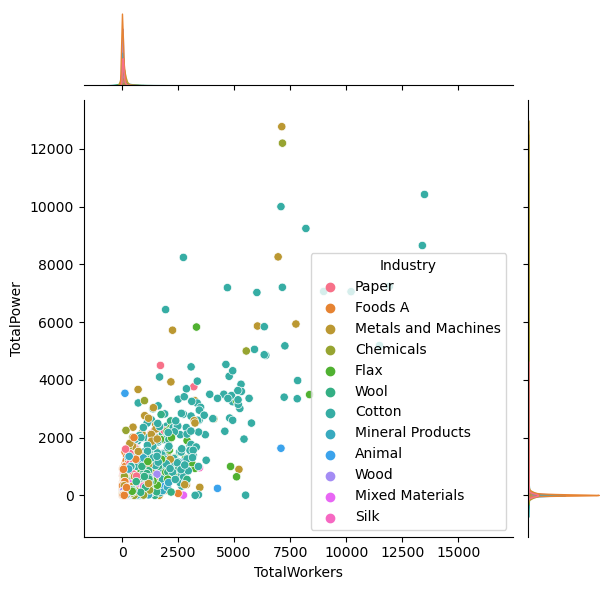
We are interested in seeing which industry in Late Imperial Russia had high machine power (measured in horsepower) and have high number of workers. We also want to get a sense of the distribution of machine power and number of workers, and visualize them by industry. Hence, let’s focus on the picture below. We see that roughly, factory with more machine power tend to also have more workers, and most company cluster at the \(2000\) horse power level, and \(2500\) workers.
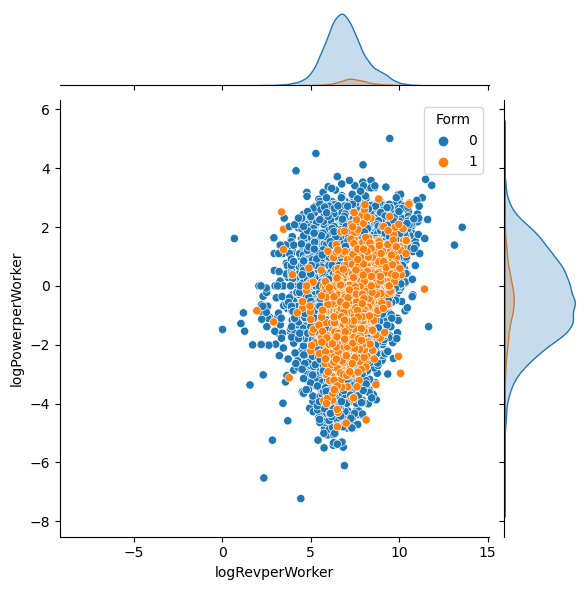
Similarly, here’s another plot to visualize the unbalanced nature of the data set. Here, Form is the desired label that we want to predict. Form taking a value of \(1\) means that factory was incorporated, i.e., it was owned by a incorporated firm. If Form take the value of \(0\), then that factory was not incorporated. In the next plot, instead of TotalPower, which stands for Total amount of horse power and TotalWorkers, which stands for total number of workers, we use logPowerperWorker and logRevperWorker as our y-axis and our x-axis. logPowerperWorker is obtained by taking the log of \(\frac{Power}{Worker}\), and logRevperWorker is log of \(\frac{Revenue}{Worker}\). And the hue is whether the factory is encorporated or not. Again, we see that the orange dots, which corresponds to \(1\), which corresponds to encorporated, is a very small percentage of all the factories. Most factories are not encorporated. Also, we observe that the data points follows a bell-shaped distribution on the two dimensions.
Materials and Methods
Predicting whether Russian Factories want to incorporate or not
We download the replication data set and put it in the same directory as our project. After we read in the data, we notice that there are \(66\) columns, which means potentially we could have around \(60\) features for our machine learning model. However, let’s start small. Hence, we begin our analysis using a subset of the columns. Also, since in the original data set, there’s only a small percentage of factories that are incorporated, which is because of historical reasons in Late Imperial Russia during 1894 to 1908. For the purpose of this machine learning project, we artificially select a subset of the whole data set so that we have equal number of factories owned by incorporated firms and not incorporated firms alike.
First approach, rebalance the data set by random sampling
We start our analysis by using logistic regression to predict what kind of firms in late Imperial Russia is more likely owned by a corporation. Since our data is not balanced, we use several different approach to this problem and try them one at a time. Luckily for us, classification problem with unbalanced data labels is quite common, so we have many approaches at our disposal.
Code
data set dimension of not incorporated: (37895, 66)
data set dimension of incorporated: (2393, 66)Let us first get out definitions straight. Unbalanced data refers to those datasets where the target label has an uneven distribution of observations, First, we try to randomly sample the majority data set, which in this case, is when the label equals unincorporated. Then we keep all the data entries of the minority data set, and add in the randomly sampled extract of the majority data set with size equal to the minority data set. Then we perform logistic regression on this new data set. The good news is that our new data set is balanced, and the bad news is that we loose a lot of information by discarding many data entries in the majority data set.
Code
df incorporated have 2393 many rows
after balancing, df not incorporated have 2393 many rowsWe could also create a under-sampling of the data set where though discarding data points of the majority data set, we achieve a balanced data set, albeit using a small subset of the full data set. Let’s store this balanced data set in the variable called result. We will mainly use the unbalanced full data set, but result data set is quite useful for testing and experimenting during our investigation.
Let us try the Logistic regression using Newton_Raphson method that we implemented from scratch on this balanced data set. We see that it converged rather quickly, and our score is high for all three groups: training, testing, validation.
Code
learning rate is: 0.5
Regularization is: True/home/xianzhiwang/ml0451/ml-0451-final-proj/posts/final-blog-post/newton_raphson.py:35: RuntimeWarning: overflow encountered in exp
return 1/(1+np.exp(-x))number of iteration: 10
beta: [[-949.3769919 ]
[-491.51336087]
[-514.56704713]]
number of iteration: 20
beta: [[ 616.1139379 ]
[ -77.70969872]
[-1728.53996285]]
number of iteration: 30
beta: [[ 249.78344405]
[ 8.25635669]
[-1099.30023336]]
number of iteration: 40
beta: [[ 109.88147514]
[ 3.71503689]
[-483.75986262]]
number of iteration: 50
beta: [[ 1.13087712]
[ 0.09177811]
[-4.96515977]]
number of iteration: 60
beta: [[ 0.97942233]
[ 0.109256 ]
[-4.31855225]]
number of iteration: 70
beta: [[ 0.97926744]
[ 0.10927011]
[-4.31788045]]
number of iteration: 80
beta: [[ 0.97926724]
[ 0.10927013]
[-4.31787959]]
number of iteration: 90
beta: [[ 0.97926724]
[ 0.10927013]
[-4.31787959]]
number of iteration: 100
beta: [[ 0.97926724]
[ 0.10927013]
[-4.31787959]]
Converged with 101 iterations
The beta we end up with is: [[ 0.97926724]
[ 0.10927013]
[-4.31787959]]Code
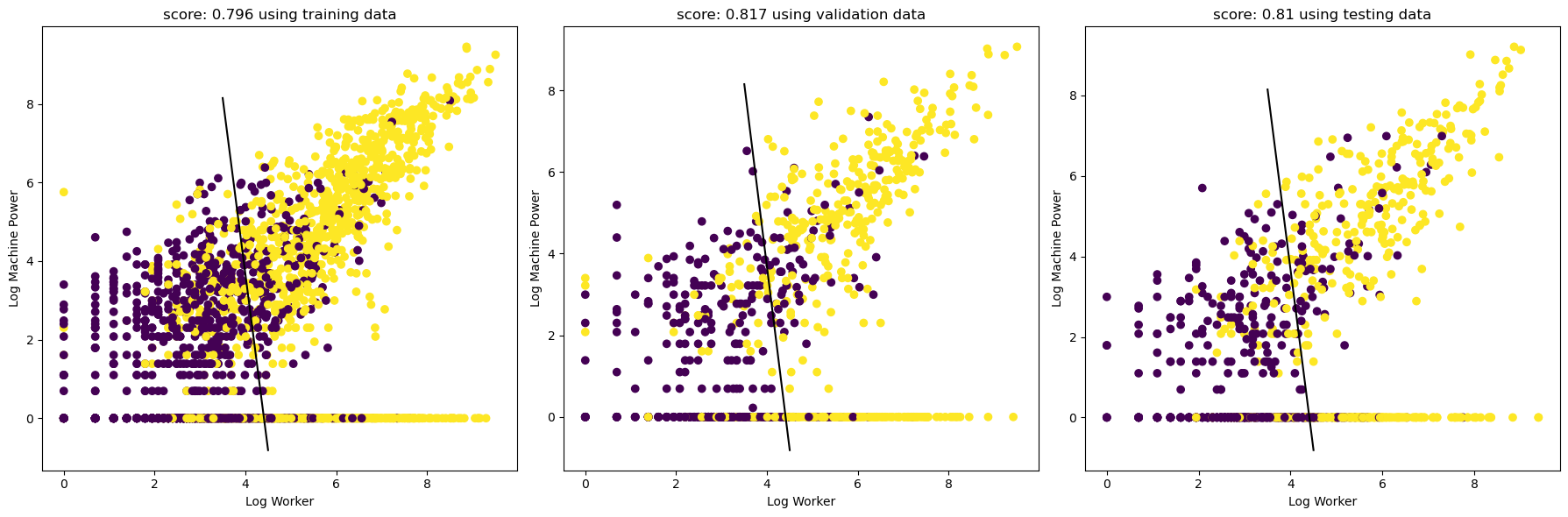
The pictures looks good! The horizontal axis is log of total number of factory workers, and the vertical axis is log of total machine power measured in horse power. We see that factories with more workers and more machine power (on a log scale) are much more likely to incorporate. Since this is log scale, we deduce that factories with significantly more worker and more power tend to incorporate.
Let’s do more visualization!
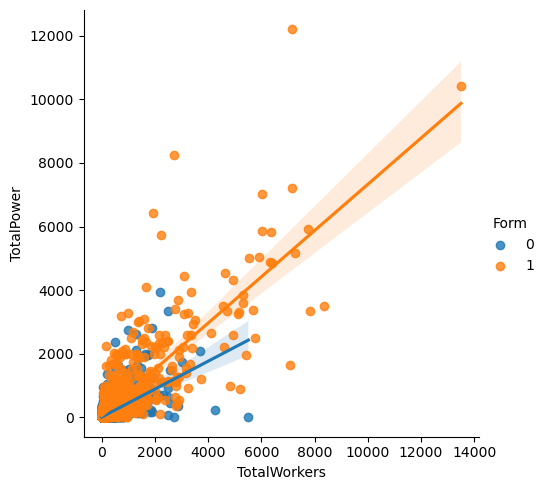
We see that most factories have around \(1000\) to \(2000\) workers, and they have around \(0\) machine power to \(2000\) machine power, measured in horse power. There’s also a rough linear trend between total power and total worker, which makes sense. Factories with more power tend to have more workers, and vice versa.
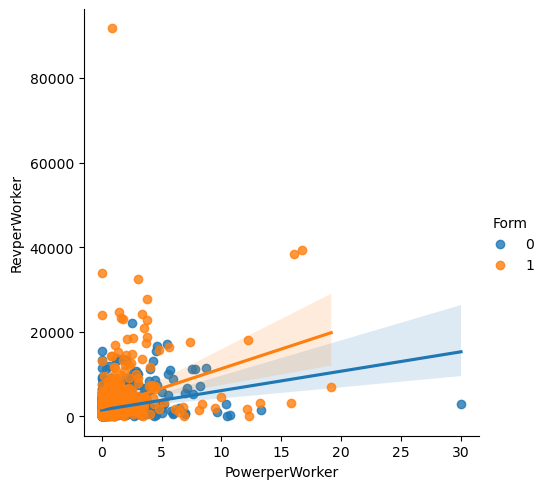
Here, we also see that there is a linear trend between Power per worker and Revenue per worker. It seems that factories that are not incorpored (those with Form == 0) tend to have more power per worker given the same revenue per worker, compared to their incorporated counterparts.
Now, we try some feature engineering
Whether to incorporate or not is an interesting question for factories and firms in late Imperial Russia. There were many factors that might affect a firm’s decision to incorporate or not, including the overall size of the factory, which could be seen in features such as total machine power of the factory and the total number of workers in a factory. Other factors such as the geographical location of the factory (i.e. which region it was located in) could also play a role. Since the decision to incorporate could be affected by many features, we see that some feature engineering could be beneficial for our analysis.
In the basic toolbox of an economist, one is unlikely to find methods of feature engineering, since we believe that economists would rather choose the regressors (features) themselves, becuase regressors are often central to the economic questoin and analysis. However, in this project, we actually going to have a systematic way written in code to select the features, according to which combination of features gives the highest score.
Code
df incorporated have 2393 many rows
after balancing, df not incorporated have 2393 many rowsCode
We encode Region, which contains strings denoting the region of the factory in question, into numbers.
We also encode Industry into numbers, so we could run regression on it.
Now, we try all feature combinations and select the one with the highest score according to logistic regression.
Code
FP1 = FinalProject()
all_qual_cols = ['RegionCoded', 'IndustryCoded', "IndustryFactorCoded"]
all_quant_cols = [
'Province', 'OntheSide', 'Age', 'TaxedActivity',
'YEAR', 'SubindustryCode', 'STCAP', 'Revenue',
'TotalWorkers', 'TotalPower', 'GrandTotalWorkers', 'RevperWorker',
'PowerperWorker', 'RevperGrandWorker', 'PowerperGrandWorker',
'logRevperWorker', 'logPowerperWorker', 'logRevperGrandWorker',
'logPowerperGrandWorker', 'logRev', 'logWorkers', 'logPower',
'RegIndGroup', 'RegIndYearGroup', 'ProvIndGroup', 'ProvIndYearGroup',
'IndYearGroup', 'ProvinceFactor', 'YearFactor',
'AKTS', 'PAI', 'factory_id', 'FormNextYear', 'FormNextNextYear',
'FactoryisCorpin1894', 'FormNextYearin1894', 'FactoryisCorpin1900',
'FormNextYearin1900', 'FactoryisCorpin1908', 'NEWDEV', 'SHARES',
'STPRICE', 'BONDS', 'Silk', 'Flax', 'Animal', 'Wool', 'Cotton',
'MixedMaterials', 'Wood', 'Paper', 'MetalsandMachines', 'Foods',
'Chemical', 'Mineral']
y_train = y_train.reset_index(drop=True)
FP1.feature_combo(all_qual_cols, all_quant_cols, X_train, y_train) /home/xianzhiwang/miniforge3/envs/ml-0451/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py:458: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(We see that it took a very long time to run! Now, let’s print out the column conbination with the highest score!
('RegionCoded', 'FactoryisCorpin1900', 'NEWDEV')The highest scoring combination is “RegionCoded”, “FactoryisCorpin1900”, “NEWDEV”, which together gives a logistic regression score of \(0.993\).
Another combination that we also considered during the experimenting phase is RegionCoded, RevperGrandWorker, logWorkers, which has a score of \(0.808\), which is not bad!
Code
0.9947753396029259
0.8164402647161267
0.9947753396029259Now, let’s use the Newton Raphson method that we implemented from scratch on those three columns!
Code
cols = ["RegionCoded", "FactoryisCorpin1900", "NEWDEV"]
# only run once, convert to numpy
X_train, y_train = FP.make_ready_for_regression(X_train, y_train, cols)
X_validate, y_validate= FP.make_ready_for_regression(X_validate, y_validate, cols)
X_test, y_test= FP.make_ready_for_regression(X_test, y_test, cols)Code
/home/xianzhiwang/ml0451/ml-0451-final-proj/posts/final-blog-post/newton_raphson.py:36: RuntimeWarning: overflow encountered in exp
return 1/(1+np.exp(-x))number of iteration: 10
number of iteration: 20
number of iteration: 30
number of iteration: 40
number of iteration: 50
number of iteration: 60
number of iteration: 70
number of iteration: 80
number of iteration: 90
number of iteration: 100
number of iteration: 110
number of iteration: 120
number of iteration: 130
number of iteration: 140
number of iteration: 150
number of iteration: 160
number of iteration: 170
number of iteration: 180
number of iteration: 190
number of iteration: 200
number of iteration: 210
number of iteration: 220
number of iteration: 230
number of iteration: 240
number of iteration: 250
number of iteration: 260
number of iteration: 270
number of iteration: 280
number of iteration: 290
number of iteration: 300
number of iteration: 310
number of iteration: 320
number of iteration: 330
number of iteration: 340
number of iteration: 350
number of iteration: 360
number of iteration: 370
number of iteration: 380
number of iteration: 390
number of iteration: 400
number of iteration: 410
number of iteration: 420
number of iteration: 430
number of iteration: 440
number of iteration: 450
number of iteration: 460
number of iteration: 470
number of iteration: 480
number of iteration: 490
number of iteration: 500
number of iteration: 510
number of iteration: 520
number of iteration: 530
number of iteration: 540
number of iteration: 550
number of iteration: 560
number of iteration: 570
number of iteration: 580
number of iteration: 590
number of iteration: 600
number of iteration: 610
number of iteration: 620
number of iteration: 630
number of iteration: 640
number of iteration: 650
number of iteration: 660
number of iteration: 670
number of iteration: 680
number of iteration: 690
number of iteration: 700
number of iteration: 710
number of iteration: 720
number of iteration: 730
number of iteration: 740
number of iteration: 750
number of iteration: 760
number of iteration: 770
number of iteration: 780
number of iteration: 790
number of iteration: 800
number of iteration: 810
number of iteration: 820
number of iteration: 830
number of iteration: 840
number of iteration: 850
number of iteration: 860
number of iteration: 870
number of iteration: 880
number of iteration: 890
number of iteration: 900
number of iteration: 910
number of iteration: 920
number of iteration: 930
number of iteration: 940
number of iteration: 950
number of iteration: 960
number of iteration: 970
number of iteration: 980
number of iteration: 990
number of iteration: 1000Code
validation score: 0.9937304075235109
testing score: 0.9979123173277662Since we are using three features, we are not going to plot it this time. But our score is really high!
Now, we switch to using the full data set, which is unbalanced
The Prediction Question:
Can we predict which factory belongs to a incorporated company in Late Imerial Russia, during year 1894 and year 1908, by looking at other variables that are in the data?
Data Inspection
Since previously we have artificially selected a subset of our entire Russian factory data set so that we have equal number of factories belonging to incorporated firms and not incorporated firms, we expect that our label has roughly \(50 \%\) of \(1\)’s and \(50 \%\) % of \(0\)’s.
| Form | ||
|---|---|---|
| mean | len | |
| Industry | ||
| Animal | 0.022 | 2367 |
| Chemicals | 0.140 | 1030 |
| Cotton | 0.226 | 1285 |
| Flax | 0.096 | 624 |
| Foods A | 0.025 | 5674 |
| Metals and Machines | 0.091 | 3162 |
| Mineral Products | 0.046 | 2567 |
| Mixed Materials | 0.043 | 675 |
| Paper | 0.062 | 1928 |
| Silk | 0.035 | 491 |
| Wood | 0.039 | 2556 |
| Wool | 0.056 | 1813 |
Hence, it seems that Food industry in Late Imperial Russia had a low incorporation rate, which is around \(28.3 \%\). On the other hand, the Cotton industry had a relatively high incorporation rate, around \(81.4 \%\).
| TotalPower | ||
|---|---|---|
| mean | len | |
| Industry | ||
| Animal | 35.943 | 216 |
| Chemicals | 239.574 | 185 |
| Cotton | 1088.862 | 345 |
| Flax | 483.345 | 93 |
| Foods A | 72.742 | 456 |
| Metals and Machines | 321.692 | 466 |
| Mineral Products | 91.953 | 266 |
| Mixed Materials | 81.920 | 73 |
| Paper | 199.061 | 247 |
| Silk | 50.485 | 51 |
| Wood | 62.274 | 286 |
| Wool | 171.922 | 187 |
We see that Cotton industry has the highest mean total power, and Silk industry has the lowest mean total power. We might predict that industry with a higher need for capital might choose to incorporate. ### After doing feature engineering, we perform a standard regression analysis using some other columns, since we are Economists at heart. We prefer picking those regressors by ourselves… However, we only want to make 2D plots with two features, so let us only use 2 features this time. We plan to go with Revenue per total worker and log of total worker, which are RevperGrandWorker, and logWorkers. ### Running some logistic regressions and plotting ROC curves We start with the standard procedure in Econometrics, which is running regressions. We first perform some regression analysis that is close in spirit to the published paper where this replication data set is coming from, and use ROC curve and confusion matrix to assess our model performance. First, let’s get our definition straight.
True Positive Rate = True Positives / (True Positives + False Negatives)False Positive Rate = False Positives / (False Positives + True Negatives)
The ROC curve is especially useful when we want to compare directly the curve of several different models. Also, AUC, which stands for the area under the curve can be used to measure how good a model is.
Code
important_cols = ['RegionCoded', 'RevperGrandWorker', 'logWorkers']
high_scoring_cols = ["RegionCoded", "FactoryisCorpin1900", "NEWDEV"]
# X_train = X_train.drop(["Industry"], axis=1)
# X_train = X_train.drop(["Region"], axis=1)
# X_train.drop(["FoundingYear", "OntheSide", "TaxedActivity", "PSZLastYear", "PSZ1908"], axis=1)
X_train = X_train.fillna(0)
y_train.reset_index(drop=True)
# cols = ["FactoryisCorpin1900", "NEWDEV"]
cols = ['RevperGrandWorker', 'logWorkers']
# fit a model
LR = LogisticRegression(solver="newton-cg") # Newton's Method
LR.fit(X_train[cols], y_train)
LR.score(X_train[cols], y_train)0.9472943902035413Code
# compute the scores
auc_no_skill = roc_auc_score(y_test, proba_no_skill)
auc_LR = roc_auc_score(y_test, proba_positive)
print(f"Always predict zero, which is not incorporate. ROC AUC = {auc_no_skill}")
print(f"Use Logistic Regression. ROC AUC = {auc_LR}")
# fpr, tpr, thresholds = roc_curve(y_train, scores, pos_label=2)Always predict zero, which is not incorporate. ROC AUC = 0.5
Use Logistic Regression. ROC AUC = 0.8593987534204925Code
[[0.99235837 0.00764163]
[0.75641026 0.24358974]]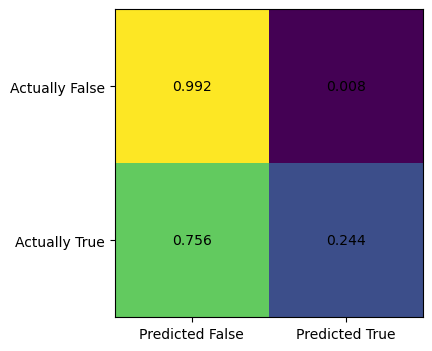
We see that there is big discrepency between the upper left corner and the lower right corner of the confusion matrix. The upper right corner is the false positive rate, which is extremely low, at \(0.008\). By contrast, the false negative rate, which is at the lower left corner, is very high, at \(0.756\). This means the logistic regression model implementing Newton’s method is very biased towards preducing false negative results, i.e., predicting a factory is not incorporated, while it is actually incorporated. This is quite consistant with our intuition, since most factories in that historical period is not incorporated, so our model would get a high score by predicting any given factory as not incorporated. Below, we plot the ROC curve.
Code
# compute roc curves
fpr_no_skill, tpr_no_skil, _ = roc_curve(y_test, proba_no_skill)
fpr_LR, tpr_LR, _ = roc_curve(y_test, proba_positive)
# plot the roc curve for the model
plt.plot(fpr_no_skill, tpr_no_skil, linestyle="--", label="No Skill")
plt.plot(fpr_LR, tpr_LR, marker='.', label='Logistic')
# axis labels
plt.xlabel('False Positive rate')
plt.ylabel('True Positive rate')
# show the legend
plt.legend()
# show the plot
plt.show()
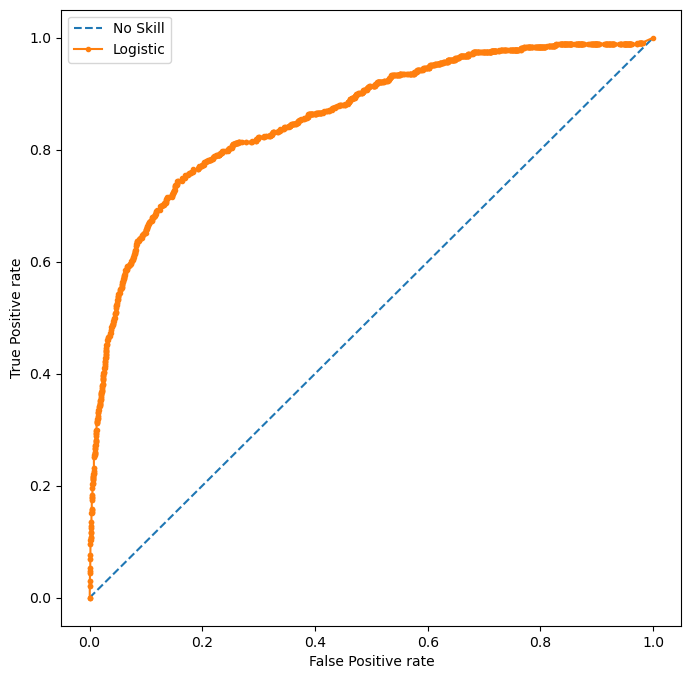
At least, logistic regression is doing much better than a no-skill predictor, which always predict not incorporate in this case.
We are interested in seeing the coefficients for the regressors in our logistic regression. We see that the coefficient for revenue per worker grand total RevperGrandWorker is \(0.000056\), and the coefficient for logWorkers, the log of the number of workers is \(1.048\). In the cells below, we are also interested in visualizing the decision region of our model. We see that the desion boundary is linear, and since our data are all relatively clustered together, the picture does not really show that our model is doing a fantastic job. It is quite hard to guess how many data points are in the correct region because of it’s quite dense.
| column | coefficient | |
|---|---|---|
| 0 | RevperGrandWorker | 0.000039 |
| 1 | logWorkers | 1.139265 |
We see that Revenue per total (grand) worker has a very small coefficient, while log workers has a much larger coefficent compared to Revenue per total worker.
<class 'pandas.core.frame.DataFrame'>
RevperGrandWorker logWorkers
7737 449.42606 5.648974
31436 2729.16670 3.178054Code
plt.rcParams["figure.figsize"]=(8,8)
print(isinstance(X_train[cols], np.ndarray))
# need to write up the function that make a visual representation
value=1.5
width=0.75
plot_decision_regions(X_test[cols].to_numpy(), y_test.to_numpy(), clf=LR
# filler_feature_values={2:value},
# filler_feature_ranges={2:width}
)
mypredict = LR.predict(X_test[cols].to_numpy())
title = plt.gca().set(title=f"Accuracy={(mypredict==y_test).mean()}",
xlabel="Revenue per Grand Worker",
ylabel="Log Workers")False/home/xianzhiwang/miniforge3/envs/ml-0451/lib/python3.9/site-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
warnings.warn(
/home/xianzhiwang/miniforge3/envs/ml-0451/lib/python3.9/site-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
warnings.warn(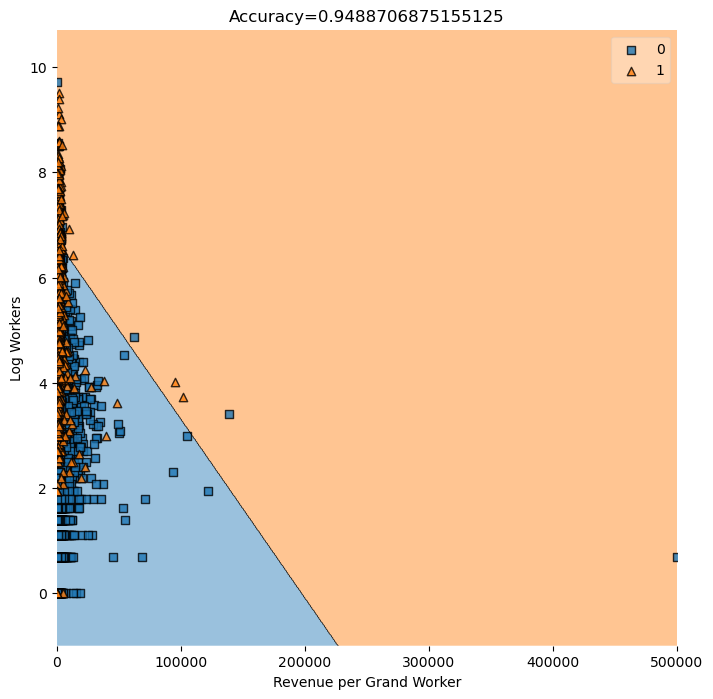
We see that factories with much more worker and much more revenue per worker is predicted to incorporate by logistic regression, which fits our intuition.
Now we try Polynomial Features
Since we are at it, let us pick two other columns, TotalWorkers, which is total number of workers, and TotalPower, which is total machine power of a factory, and run more regressions. # Use cross validation Now, we are unsure if using polynomial features would give our model more predictive power. One way to find out is by trying different degrees of polynomials and score them using cross validation. The idea behind cross validation is as follows: we divide the data into little chunks, and in each regression, one of the chunks is used as validation data set, and all other chunks are used as training data set. Each little chunk takes turn to be used for validation, hence the name cross validation. We could take the average of all those scores and use this average to compare models with different degrees.
Let us start with using degree \(2\) polynomial feature, which is like adding quadratic terms. Also, let us suppress the warning messages.
Code
[0.93960703 0.93940021 0.93959454 0.9391808 0.93959454]Hey, our scores are pretty high!
Hence, this is telling us that for the features we selected, polynomial logistic regression has roughly the same predictive power as simply guessing whether a factory is belonging to a corporation or not. Degree zero corresponds to the baseline model, and degree 1 corresponds to simple logistic regression without a polynomial feature map.
In the above code snippets, we defined a model using degree 2 polynomial features, did cross validation by dividing data into 5 chunks, and then we take the mean to get the final score. Now, we put this into a function with a for loop, that will lop through each number of polynomial degree and give us a score.
Code
Polynomial degree = 0, score = 0.94
Polynomial degree = 1, score = 0.947
Polynomial degree = 2, score = 0.939
Polynomial degree = 3, score = 0.94Hence, we see that degree one has the highest score, meaning that we just need simple logistic regression in this case. Since this score comes from cross validation, we could rely on the accuracy of this score to some extent. Now, we use simple logistic regression with no polynomial features to fit our training data once again, and we test on the testing data.
Code
0.9472116498427933
0.9489We get a score of \(0.949\), which is not bad! Also, let us print out the classification report for our model. Again, our precision score is not bad!
precision recall f1-score support
0 0.96 0.99 0.97 7590
1 0.66 0.24 0.36 468
accuracy 0.95 8058
macro avg 0.81 0.62 0.66 8058
weighted avg 0.94 0.95 0.94 8058
Code
[[7532 58]
[ 354 114]]
[[0.99235837 0.00764163]
[0.75641026 0.24358974]]Recall that the confusion matrix is organized as follows, so we could read the data right off the matrix. \[
\begin{matrix}
\text{True Positive} & \text{False Positive} \\
\text{False Negative} & \text{True Negative} \\
\end{matrix}
\] In our case, we have \(7532\) true positives and \(114\) true negatives for our test data, and \(58\) false positives and \(354\) false negatives. This is not evenly distributed, our model does give more false negatives than false positives, not the other way round. Hence, our model’s prediction is slightly biased. Also, by specifying normalize = "true", we could get the True Positive Rate (TPR), False Positive Rate (FPR), and so on. Feel free to check the definition given above earlier.
Now, let’s find out the mean machine power per worker for our testing set X_test, which is \(0.6\). Now, we would like to filter our test data X_test and only keep the entries that have more than average power per worker. Then we print out our compusion matrix again just for those entries with more than average machine power per worker. We are interested to see if our model is biased or not, in the sense that it might give more False Positives than False Negatives, or the other way round.
Code
Factories with more power per worker than average
The percentage our prediction is correct: 0.9391592920353983array([[1662, 13],
[ 97, 36]])We see that our model has predicted false negative for \(97\) cases, and false positive for \(13\) cases for factories with more power per worker than average. Hence, in this case, our model is slightly biased towards false negative, predicting the factory is not incorporated (negative) when the factory is actually incorporated (positive). This makes economic sense, since we have selected only factories with above average machine power, and since factories with more machine power stood to gain more investment and capital if they incorporate, they were more likely to incorporate than average, so our model, which is trained on all the entries in X_train, has predicted more false negatives for factories with more power, and this fits our economic intuition.
Code
ix = X_test["PowerperWorker"] < 0.63483127
print("Factories with less power per worker than average")
print(f"The percentage our prediction matches the actual label: {(y_test[ix] == y_predict[ix]).mean()}")
print(confusion_matrix(y_test[ix], y_predict[ix]))
print(confusion_matrix(y_test[ix], y_predict[ix], normalize="true"))Factories with less power per worker than average
The percentage our prediction matches the actual label: 0.95168
[[5870 45]
[ 257 78]]
[[0.99239222 0.00760778]
[0.76716418 0.23283582]]We do the exact same thing for restricting our data set to only factories with less machine power per worker than average. The situation is exactly flipped, since we have more false positive than false negative. Our model tend to predict incorporated when the factory was not incorporated. This is consistent with our findings earlier, since we are in the exact flip case, where we restrict to factories with less machine power, and those are factories that potentially benefit less from the access to more captial and credit brought by incorporation, since they are not perticularly machine intensive. Hence, they had a slightly lower probability to incorporate.
Logistic regression implementing Newton’s Method from sklearn
We first try the logistic regression from sklearn on the entire data set, and see how it handles the unbalanced data.
Code
from matplotlib import pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from itertools import combinations
from matplotlib.patches import Patch
import seaborn as sns
from mlxtend.plotting import plot_decision_regions
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from final_project_code import FinalProject
from newton_raphson import Newton_Raphson
from final_plot import plot_stuff
FP = FinalProject()
df = pd.read_csv("./AG_Corp_Prod_DataBase.csv")/tmp/ipykernel_1254/1443741698.py:21: DtypeWarning: Columns (3,13) have mixed types. Specify dtype option on import or set low_memory=False.
df = pd.read_csv("./AG_Corp_Prod_DataBase.csv")Use Logistic Regression from sklearn
/home/xianzhiwang/miniforge3/envs/ml-0451/lib/python3.9/site-packages/sklearn/utils/validation.py:1143: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)the coefficients are: [[0.61083052 0.12349061]]
the intercept is: [-9.70437108]Code
value=1.5
width=0.75
y_train = y_train.reshape(-1)
plot_decision_regions(X_train, y_train, clf=Reg
# filler_feature_values={2:value},
# filler_feature_ranges={2:width}
)
mypredict = Reg.predict(X_train)
title = plt.gca().set(title=f"Accuracy={(mypredict==y_train).mean()}",
xlabel="Log Revenue",
ylabel="Log Power")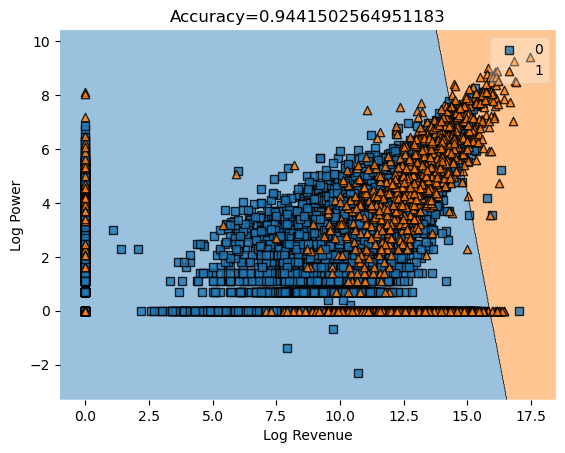
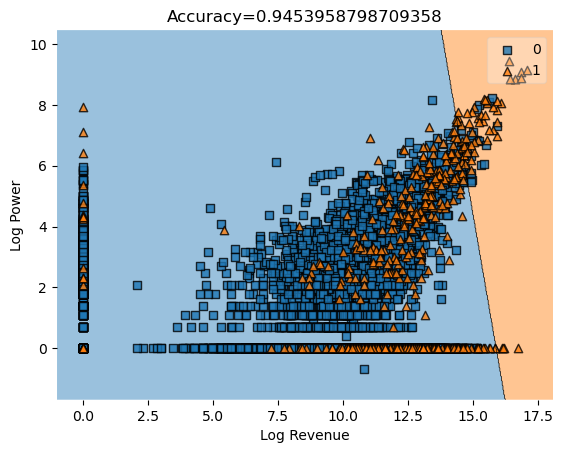
Results
Using our own implementation of Newton’s method logistic regression from scratch on Balanced data. We switched to using the balanced data so it’s a smaller, cleaner data set that’s more friendly to our computer hardware.
Code
df incorporated have 2393 many rows
after balancing, df not incorporated have 2393 many rowsCode
/home/xianzhiwang/ml0451/ml-0451-final-proj/posts/final-blog-post/newton_raphson.py:36: RuntimeWarning: overflow encountered in exp
return 1/(1+np.exp(-x))number of iteration: 10
number of iteration: 20
number of iteration: 30
number of iteration: 40
number of iteration: 50
number of iteration: 60
number of iteration: 70
number of iteration: 80
number of iteration: 90
number of iteration: 100
number of iteration: 110
number of iteration: 120
number of iteration: 130
number of iteration: 140
number of iteration: 150
Converged with 155 iterations
The beta we end up with is: [[ 0.34387955]
[ 0.19512663]
[-4.12599512]]Code
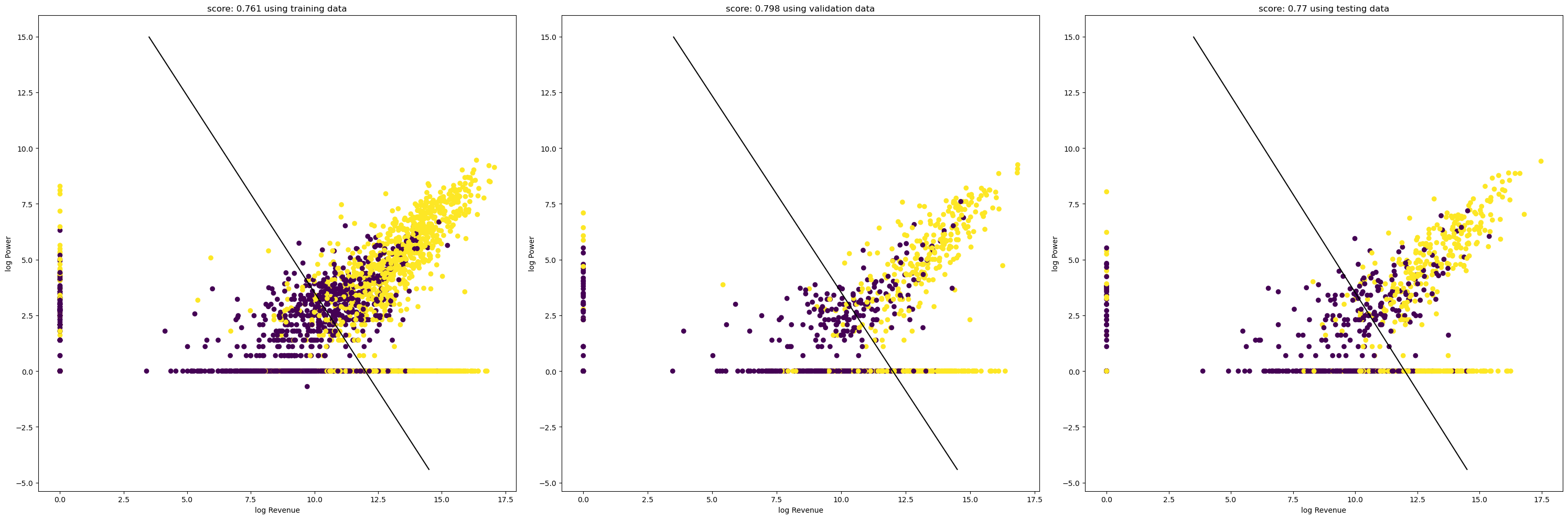
Code
0.7607105538140021
0.7703549060542797
0.7983281086729362Code
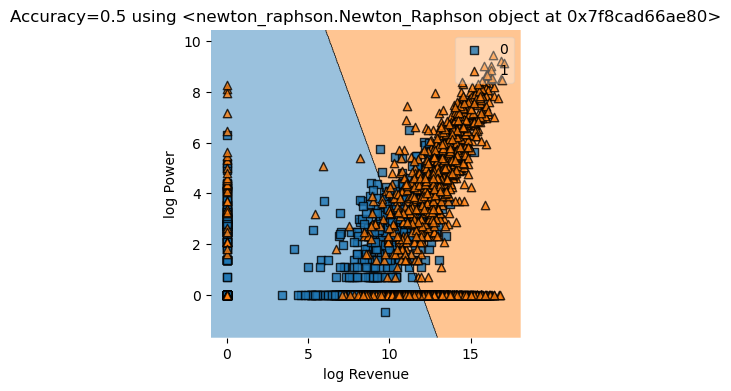
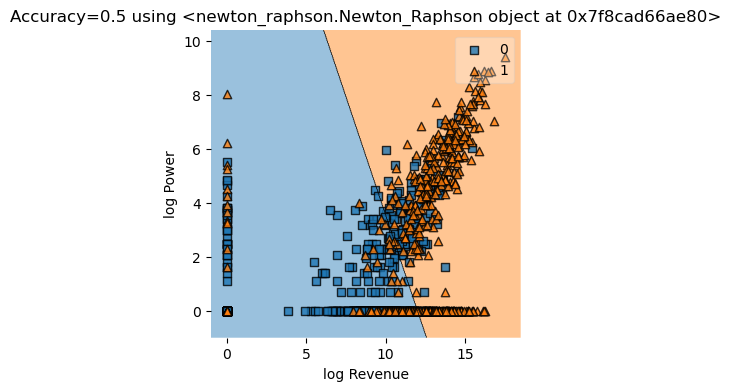
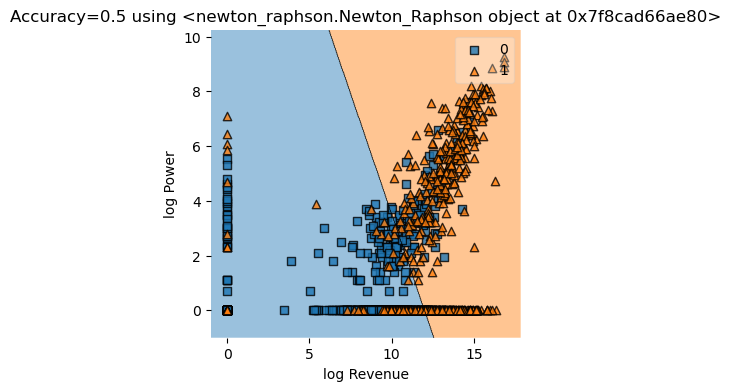
Using Logistic regression from Sklearn for comparison
array([[0.34376508, 0.19507788]])Code
0.7703549060542797
0.7607105538140021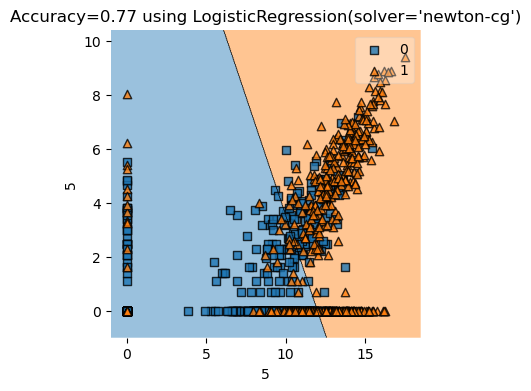
Conclusion
In conclusion, our implementation of the Newton’s method logistic regression works quite well on our data with just 2 features. We could use more features, but it takes longer to run on our laptops, so it becomes less convinient to experiment with different features and visualizations. We also used confusion matrix and ROC curve to measure the bias in the model and evaluate it’s performance. Since our data is very unblanced, due to the historical fact that only a few factories were incorporated during that historical time period in Late Imperial Russia. In the end, logistic regression still achieves around \(0.8\) accuracy with many column combinations that we tried, so it was not bad, even though the model is heavily biased towards predicting negative, which is not incorporate, hence giving a disproportionally many false negatives. However, this fits our economic intuition, and makes common sense: after all, if we were to guess, then guessing not incorporated is a much better guess than guessing incorporated, due to the unbalanced data set. Still ROC curve shows that logistic regression is doing better than the no-skill predictor, so we are still better off with a model than no model at all.
Group Contributions
Prateek worked on Introduction, Visualization, Value Statements, and Project Proposal. Xianzhi worked on Code implementation, Newton’s Method, Confusion Matrix, ROC curve, plotting graphs, and Conclusion.
Xianzhi’s personal reflection:
I have learned a lot about debugging during the process of researching and implementing my project. I learned a lot about turning mathematics and equations to code, and how to check my implementation, how to test my code after seeing error messages, and how to keep teeking the code so it works as intended. In summary, I have strengthened my skill at implementing mathematical equations into a working piece of python program.
Prateek’s personal reflection
Appendix: References
Our main reference is Gregg (2020)
We also need Bishop (2013)
Appendix: Source Code
The Python source files used in this post are reproduced below so that readers of the rendered site can inspect the implementation without needing access to the underlying repository.
final_project_code.py
import numpy as np
from sklearn.datasets import make_blobs
from matplotlib.patches import Patch
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from matplotlib.patches import Patch
import matplotlib.pyplot as plt
from itertools import combinations
from sklearn.linear_model import LogisticRegression
le = LabelEncoder()
# for plotting decision region
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from mlxtend.plotting import plot_decision_regions
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
class FinalProject:
def __init__(self) -> None:
self.qual_cols = None
self.feature_score_pair = dict()
self.beta = None
self.mypredict = None
def try_to_plot_decision_regioin(self, X_train, y_train, cols):
clf = SVC(C=100,gamma=0.0001)
pca = PCA(n_components = 2)
X_train2 = pca.fit_transform(X_train[cols].to_numpy())
clf.fit(X_train[cols], y_train.to_numpy())
plot_decision_regions(X_train[cols].to_numpy(), y_train.to_numpy(), clf=clf, legend=2)
plt.xlabel(X_train[cols].to_numpy().columns[0], size=14)
plt.ylabel(X_train[cols].to_numpy().columns[1], size=14)
plt.title('SVM Decision Region Boundary', size=16)
def convert_stata(self):
'''
We only need to use this function once, and in subsequent analysis, we simply load in the .csv file.
'''
Rvss = pd.io.stata.read_stata("./../Rvssian/AG_Corp_RuscorpMasterFile_Cleaned.dta")
Rvss.to_csv("RvssianCorpMasterFileCleaned.csv")
Rvss_data = pd.io.stata.read_stata("./AG_Corp_Prod_Database.dta")
Rvss_data.to_csv("AG_Corp_Prod_DataBase.csv")
def make_ready_for_regression(self, X, y, cols):
# X
X = X[cols]
X = X.fillna(0)
X = X.to_numpy()
# y
y = y.fillna(0)
y = y.to_numpy()
y = y.reshape(-1,1)
return X,y
def create_balanced_data(self, df) -> pd.DataFrame:
df_inc = df.loc[df['Form'] == 1]
df_not_inc = df.loc[df['Form'] == 0]
print(f"df incorporated have {df_inc.shape[0]} many rows")
df_not_inc = df_not_inc.sample(n=2393, replace=False)
print(f"after balancing, df not incorporated have {df_not_inc.shape[0]} many rows")
frames = [df_inc, df_not_inc]
result = pd.concat(frames)
result = result.sample(frac=1).reset_index(drop=True)
return result
def balanced_one_minus_one(self, df) -> pd.DataFrame:
df_inc = df.loc[df['Form'] == 1]
df_not_inc = df.loc[df['Form'] == -1]
print(f"df incorporated have {df_inc.shape[0]} many rows")
df_not_inc = df_not_inc.sample(n=2393, replace=False)
print(f"after balancing, df not incorporated have {df_not_inc.shape[0]} many rows")
frames = [df_inc, df_not_inc]
result = pd.concat(frames)
result = result.sample(frac=1).reset_index(drop=True)
return result
def plot_regions(self, model, X, y):
pass
def prepare_data(self, df):
y = df['Form']
X = df.drop(['Form'], axis = 1)
return df, X, y
def split_data(self, df):
train, validate, test = np.split(df.sample(frac=1, random_state=42), [int(.6*len(df)), int(.8*len(df))])
return train, validate, test
def feature_combo(self, all_qual_cols, all_quant_cols, df, y):
for qual in all_qual_cols:
self.qual_cols = [col for col in df.columns if qual in col ]
for pair in combinations(all_quant_cols, 2):
cols = self.qual_cols + list(pair)
# you could train models and score them here, keeping the list of
# columns for the model that has the best score.
LR = LogisticRegression()
LR.fit(df[cols], y)
score = LR.score(df[cols], y)
self.feature_score_pair[tuple(cols)] = score
def print_confusion_matrix(self, model, X, y):
my_matr = confusion_matrix(y, model.predict(X), normalize="true")
fig, ax = plt.subplots(figsize=(4,4))
ax.imshow(my_matr)
ax.xaxis.set(ticks=(0,1), ticklabels=('Predicted False', 'Predicted True'))
ax.yaxis.set(ticks=(0,1), ticklabels=('Actually False', 'Actually True'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j,i, my_matr[i,j].round(3), ha='center', va='center', color='black')
def encode_features(self, df: pd.DataFrame, var_name: str):
le = LabelEncoder()
le.fit(df[var_name])
var_name_coded = le.transform(df[var_name])
df_minus = df.drop(columns=var_name, axis = 1)
return df_minus, var_name_coded
def all_the_columns(self):
cols = ['id', 'FoundingYear', 'Province', 'OntheSide', 'Age', 'TaxedActivity',
'YEAR', 'PSZLastYear', 'PSZ1908', 'SubindustryCode', 'STCAP', 'Revenue',
'TotalWorkers', 'TotalPower', 'GrandTotalWorkers', 'RevperWorker',
'PowerperWorker', 'RevperGrandWorker', 'PowerperGrandWorker',
'logRevperWorker', 'logPowerperWorker', 'logRevperGrandWorker',
'logPowerperGrandWorker', 'logRev', 'logWorkers', 'logPower',
'RegIndGroup', 'RegIndYearGroup', 'ProvIndGroup', 'ProvIndYearGroup',
'IndYearGroup', 'IndustryFactor', 'ProvinceFactor', 'YearFactor',
'AKTS', 'PAI', 'factory_id', 'FormNextYear', 'FormNextNextYear',
'FactoryisCorpin1894', 'FormNextYearin1894', 'FactoryisCorpin1900',
'FormNextYearin1900', 'FactoryisCorpin1908', 'NEWDEV', 'SHARES',
'STPRICE', 'BONDS', 'Silk', 'Flax', 'Animal', 'Wool', 'Cotton',
'MixedMaterials', 'Wood', 'Paper', 'MetalsandMachines', 'Foods',
'Chemical', 'Mineral']
return cols
def poly_LR(self, deg):
return Pipeline([("poly", PolynomialFeatures(degree=deg)),
("LR", LogisticRegression(penalty="none", max_iter=int(1e3)))])
def polynomial_degree_validation(self, df, y, max_deg, cv):
for deg in range(max_deg):
plr = self.poly_LR(deg = deg)
cv_scores = cross_val_score(plr, df, y, cv=cv)
mean_score = cv_scores.mean()
print(f"Polynomial degree = {deg}, score = {mean_score.round(3)}")
def preparing_data(self, df):
# le.fit(df["Species"])
# df = df.drop(["studyName", "Sample Number", "Individual ID", "Date Egg", "Comments", "Region"], axis = 1)
# df = df[df["Sex"] != "."]
# df = df.dropna()
# y = le.transform(df["Species"])
# df = df.drop(["Species"], axis = 1)
# df = pd.get_dummies(df)
# return df, y
pass
newton_raphson.py
import numpy as np
from sklearn.datasets import make_blobs
from matplotlib.patches import Patch
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from matplotlib.patches import Patch
import matplotlib.pyplot as plt
from itertools import combinations
from sklearn.linear_model import LogisticRegression
le = LabelEncoder()
# for plotting decision region
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from mlxtend.plotting import plot_decision_regions
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
# Logistic Regression and Newton Raphson
class Newton_Raphson():
def __init__(self, *kernel, **kernel_kwargs):
self.kernel = kernel
self.kernel_kwargs = kernel_kwargs
self.beta_old = np.random.rand(3,1)
self.beta = np.random.rand(3,1)
self.alpha = 0.5
self.reg = True
def sigmoid(self, x: np.array):
return 1/(1+np.exp(-x))
def prob(self, X: np.array, beta: np.array):
'''
prob stands for probability
'''
return np.array(self.sigmoid(X.dot(beta)))
# return self.sigmoid(X.T @ beta)
# return self.sigmoid(X @ beta)
def Var(self, p: np.array):
'''
Var stands for Variance
'''
on_diag = p*(1-p)
d = on_diag.reshape(-1)
return np.diag(d)
def Hessian(self, X: np.array, beta: np.array):
'''
print(f"X.T.shape {X.T.shape}")
print(f"X.shape {X.shape}")
print(f"VAR.shape {V.shape}")
print(XV.shape)
'''
V = self.Var(self.prob(X,beta))
XV = X.T @ V
# result = np.dot(XV, X)
result = XV @ X
return result
def update(self, y, X, beta):
'''
print(X.T.shape)
print(y.shape)
print(self.prob(X,beta).shape)
'''
grad = X.T @ (y-self.prob(X,beta))
# reguliazation
if (self.reg):
hessian = self.Hessian(X,beta) + np.eye(beta.shape[0])
step = np.linalg.inv(hessian) @ grad
# no reguliazation
else:
hessian = self.Hessian(X,beta)
step = np.linalg.inv(hessian) @ grad
# print(f"step: {step.shape}")
step = self.alpha * step
beta = beta + step
return beta
def regress(self, y, X, max_iters = 1e1, tol=1e-8, converged=False):
X = self.patek(X)
self.beta_old = np.ones((X.shape[1],1))
# self.beta = np.array([-5.4e-02, 6.8e-02, 2.3e-2])
self.beta = np.random.rand(X.shape[1],1)
self.beta = self.beta.reshape(-1,1)
self.beta_old = self.beta_old.reshape(-1,1)
# print(f"learning rate is: {self.alpha}")
# print(f"Regularization is: {self.reg}")
iter_count = 0
while not converged and (iter_count<max_iters):
iter_count += 1
# print(f"self.beta {self.beta.shape}")
# print(f"self.beta_old {self.beta_old.shape}")
self.beta = self.update(y, X, self.beta)
if (iter_count % 10 == 0):
print(f"number of iteration: {iter_count}")
# print(f"beta: {self.beta}")
if not np.any(np.abs(self.beta_old - self.beta)>tol):
converged = True
print(f"Converged with {iter_count} iterations")
print(f"The beta we end up with is: {self.beta}")
self.beta_old = self.beta
# self.beta = self.beta.to_numpy()
def predict(self, X):
X = self.patek(X)
innerProd = X @ self.beta
y_hat = 1 * (innerProd > 0)
return y_hat
def score(self,X,y):
y = y.reshape(-1)
mypredict = self.predict(X)
mypredict = mypredict.reshape(-1)
myscore = 1 * (mypredict == y)
return myscore.mean()
def simple_plot(self, model, X, y, F1,F2):
y = y.reshape(-1)
plot_decision_regions(X, y, clf=model)
self.mypredict = model.predict(X)
score = (self.mypredict==y).mean()
title = plt.gca().set(title=f"Accuracy={round(score,3)} using {model}",
# title = plt.gca().set(title=f"Accuracy using {model}",
xlabel=F1,
ylabel=F2)
def bare_bone_plot(self, X, y, size_1, size_2):
plt.rcParams["figure.figsize"] = (size_1,size_2)
mypredict = self.predict(X)
score = (mypredict == y).mean()
print(f"the weight beta is: {self.beta}")
a_0 = self.beta[0][0]
a_1 = self.beta[1][0]
a_2 = self.beta[2][0]
fig = plt.scatter(X[:,0], X[:,1], c = y)
xlab = plt.xlabel("Feature 1")
ylab = plt.ylabel("Feature 2")
f1 = np.linspace(3.5, 4.5, 501)
p = plt.plot(f1, -(a_2/a_1) - (a_0/a_1)*f1, color = "black")
title = plt.gca().set_title(f"score is: {round(score,3)}")
def helper_plot(self, X, y, subplot, label, F1,F2):
'''
Helper method for big_plot
'''
score = self.score(X,y)
a_0 = self.beta[0][0]
a_1 = self.beta[1][0]
a_2 = self.beta[2][0]
fig = subplot.scatter(X[:,0], X[:,1], c = y)
subplot.set(xlabel=F1, ylabel=F2, title=f"score: {round(score, 3)} using {label} data")
# the line
f1 = np.linspace(3.5, 14.5, 501)
p = subplot.plot(f1, -(a_2/a_1) - (a_0/a_1)*f1, color = "black")
def big_plot(self, X_train, y_train, X_validate, y_validate, X_test, y_test, size_1, size_2, F1, F2):
plt.rcParams["figure.figsize"] = (size_1,size_2)
fig, axarr = plt.subplots(1,3)
self.helper_plot(X_train, y_train, axarr[0], "training", F1, F2)
self.helper_plot(X_validate, y_validate, axarr[1], "validation", F1, F2)
self.helper_plot(X_test, y_test, axarr[2], "testing", F1, F2)
plt.tight_layout()
def patek(self, X: np.array) -> np.array:
'''
Certified pre-owned bust-down patek function for padding
'''
return np.append(X, np.ones((X.shape[0],1)), 1)
final_plot.py
import numpy as np
from matplotlib.patches import Patch
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from matplotlib.patches import Patch
import matplotlib.pyplot as plt
from itertools import combinations
from sklearn.linear_model import LogisticRegression
le = LabelEncoder()
# for plotting decision region
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from mlxtend.plotting import plot_decision_regions
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
class plot_stuff():
def __init__(self) -> None:
self.w = None
def plot_regions(self, model, X, y):
x0 = X[X.columns[0]]
x1 = X[X.columns[1]]
qual_features = X.columns[2:]
fig, axarr = plt.subplots(1, len(qual_features), figsize = (7, 3))
# create a grid
grid_x = np.linspace(x0.min(),x0.max(),501)
grid_y = np.linspace(x1.min(),x1.max(),501)
xx, yy = np.meshgrid(grid_x, grid_y)
XX = xx.ravel()
YY = yy.ravel()
for i in range(len(qual_features)):
XY = pd.DataFrame({
X.columns[0] : XX,
X.columns[1] : YY
})
for j in qual_features:
XY[j] = 0
XY[qual_features[i]] = 1
p = model.predict(XY)
print(f"p{p}")
print(type(p))
p = p.to_numpy()
p = p.reshape(xx.shape)
# use contour plot to visualize the predictions
# axarr[i].contourf(xx, yy, p, cmap = "jet", alpha = 0.2, vmin = 0, vmax = 2)
plt.contourf(xx, yy, p, cmap = "jet", alpha = 0.2, vmin = 0, vmax = 2)
ix = X[qual_features[i]] == 1
# plot the data
# axarr[i].scatter(x0[ix], x1[ix], c = y[ix], cmap = "jet", vmin = 0, vmax = 2)
plt.scatter(x0[ix], x1[ix], c = y[ix], cmap = "jet", vmin = 0, vmax = 2)
# axarr[i].set(xlabel = X.columns[0],
# ylabel = X.columns[1])
# patches = []
# for color, spec in zip(["red", "green", "blue"], ["Adelie", "Chinstrap", "Gentoo"]):
# patches.append(Patch(color = color, label = spec))
# plt.legend(title = "Species", handles = patches, loc = "best")
plt.tight_layout()
# from internet
# decision surface for logistic regression on a binary classification dataset
def draw(self, X, y, yhat):
# generate dataset
# X, y = make_blobs(n_samples=1000, centers=2, n_features=2, random_state=1, cluster_std=3)
# define bounds of the domain
min1, max1 = X[:, 0].min()-1, X[:, 0].max()+1
min2, max2 = X[:, 1].min()-1, X[:, 1].max()+1
# define the x and y scale
x1grid = np.arange(min1, max1, 0.1)
x2grid = np.arange(min2, max2, 0.1)
# create all of the lines and rows of the grid
xx, yy = np.meshgrid(x1grid, x2grid)
# flatten each grid to a vector
r1, r2 = xx.flatten(), yy.flatten()
r1, r2 = r1.reshape((len(r1), 1)), r2.reshape((len(r2), 1))
# horizontal stack vectors to create x1,x2 input for the model
grid = np.hstack((r1,r2))
# define the model
# model = LogisticRegression()
# fit the model
# model.fit(X, y)
# make predictions for the grid
# yhat = model.predict(grid)
# reshape the predictions back into a grid
zz = yhat.reshape(xx.shape)
# plot the grid of x, y and z values as a surface
plt.contourf(xx, yy, zz, cmap='Paired')
# create scatter plot for samples from each class
for class_value in range(2):
# get row indexes for samples with this class
row_ix = np.where(y == class_value)
# create scatter of these samples
plt.scatter(X[row_ix, 0], X[row_ix, 1], cmap='Paired')
References
Bishop, C. M. 2013. Pattern Recognition and Machine Learning: All "Just the Facts 101" Material. Information Science and Statistics. Springer (India) Private Limited. https://books.google.com/books?id=HL4HrgEACAAJ.
Gregg, Amanda G. 2020. “Factory Productivity and the Concession System of Incorporation in Late Imperial Russia, 1894–1908.” American Economic Review 110 (2): 401–27. https://doi.org/10.1257/aer.20151656.