import numpy as np
from sklearn.datasets import make_blobs
from matplotlib.patches import Patch
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from matplotlib.patches import Patch
import matplotlib.pyplot as plt
from itertools import combinations
from sklearn.linear_model import LogisticRegression
le = LabelEncoder()
# for plotting decision region
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from mlxtend.plotting import plot_decision_regions
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
class supp_vec_machine():
def __init__(self, row_length=3, C=10, b=0.0001) -> None:
self.C = C
self.b = b
self.row_length = row_length
self.weights = np.random.randn(self.row_length)
self.weights_old = np.random.randn(self.row_length)
self.beta = None
def fit(self, X, y, max_iter=1e3, alpha=0.1, tol=1e-6, lamb=1.5):
'''
We pad X once right after calling regress
'''
i = 0
j = 1
X = self.patek(X)
n = X.shape[0]
p = X.shape[1]
self.weights = self.weights.reshape(-1,1)
term = self.C * (X.T @ y)
term = term.reshape(-1,1)
y = y.reshape(-1,1)
converged = False
lamb = lamb
while j < max_iter and not converged:
y_row = y.reshape(1, -1)
# dot_prod = y_row @ self.y_hat(X)
# print(f"dot_prod: {dot_prod}")
# dLdy_dydw = (1*(dot_prod<1)) * (y @ np.sum(X, axis = 0))
# term = np.sum(dLdy_dydw* X, axis = 0)
# term = term.reshape(-1,1)
# print(f"term: {term}")
dLdy_dydw = 0
for i in range(n):
yy_hat = y[i,0] * self.y_hat(X)[i,0]
dLdy_dydw = dLdy_dydw + (1*(yy_hat <1)) * (y[i,0]) * (X[i, :].reshape(-1,1))
term = dLdy_dydw/n
term = term.reshape(-1,1)
# print(f"term: {term}")
nabla_weight = lamb * self.weights - term
# y_hat = self.y_hat(X)
# y_hat = y_hat.reshape(-1,1)
nabla_weight = nabla_weight.reshape(-1,1)
# print("nabla_weight 2")
# print(nabla_weight.shape)
alpha = 1 / (lamb * j)
# update self.weights
self.weights = self.weights - alpha*(nabla_weight)
# nabla_b = -y * self.b
# nabla_b = np.where(1-y_hat<=0, 0, nabla_b)
# nabla_b = sum(nabla_b)
# self.b = -nabla_b * alpha / n
if j % 500 == 0:
print(f"iter_count: {j}")
j = j + 1
if not np.any(np.abs(self.weights_old- self.weights)>tol):
converged = True
print(f"Converged with {j} iterations")
print(f"The weights we end up with is: {self.weights}")
self.weights_old = self.weights
self.beta = self.weights
def y_hat(self, X):
'''
y_hat = W^T * X + b
b is the bias term
'''
# self.b = self.b.reshape(-1,1)
self.weights = self.weights.reshape(-1,1)
# y_hat = (X @ self.weights) + self.b
y_hat = (X @ self.weights)
# y_hat = np.dot(X,self.weights) + self.b
y_hat = y_hat.reshape(-1,1)
return y_hat
def hinge_loss(self,y,y_hat):
''' xi = max(1- y*y_hat, 0) '''
y = y.reshape(-1)
y_hat = y_hat.reshape(-1)
xi = 1 - y * y_hat
return np.where(xi<0, 0, xi)
def loss_function(self, xi: np.array) -> np.array:
'''
should we devide by length?
'''
self.weights = self.weights.reshape(-1,1)
wTw = self.weights.T @ self.weights
HingeLossSum = self.C * np.sum(xi)
return wTw + HingeLossSum
def nabla_weight(self, term):
'''
this is the gradient
Loss, aka Labrangian
nabla Loss = w - sum C * y_i * x_i
'''
self.weights = self.weights.reshape(-1,1)
nabla = self.weights - term
return nabla
def patek(self, X: np.array) -> np.array:
'''
Certified pre-owned bust-down patek function for padding
'''
return np.append(X, np.ones((X.shape[0],1)), 1)
def regress(self, X, y, max_iter=1e3, alpha=0.1, tol=1e-8):
'''
We pad X once right after calling regress
'''
i = 0
X = self.patek(X)
n = X.shape[0]
p = X.shape[1]
self.weights = self.weights.reshape(-1,1)
term = self.C * (X.T @ y)
term = term.reshape(-1,1)
y = y.reshape(-1,1)
converged = False
while i < max_iter and not converged:
nabla_weight = self.nabla_weight(term)
y_hat = self.y_hat(X)
# y_hat = y_hat.reshape(-1,1)
nabla_weights = np.zeros((p,n))
for w in range(self.weights.shape[0]):
# print(w)
# print(nabla_weight)
# nabla_weight[w] = np.where(np.any(1-y_hat<=0), self.weights[w], nabla_weight[w])
dummy = np.where((1 - y_hat)<=0, self.weights[w], nabla_weight[w])
dummy = dummy.reshape(-1)
nabla_weights[w] = dummy
# print("nabla_weight 1")
# print(nabla_weight.shape)
nabla_weight = np.sum(nabla_weights, axis=1)
# print(nabla_weight)
nabla_weight = nabla_weight.reshape(-1,1)
# print("nabla_weight 2")
# print(nabla_weight.shape)
# update self.weights
self.weights = self.weights - alpha*(nabla_weight/n)
nabla_b = -y * self.b
nabla_b = np.where(1-y_hat<=0, 0, nabla_b)
nabla_b = sum(nabla_b)
self.b = -nabla_b * alpha / n
if i % 10 == 0:
print(f"iter_count: {i}")
i = i + 1
if not np.any(np.abs(self.weights_old- self.weights)>tol):
converged = True
print(f"Converged with {i} iterations")
print(f"The weights we end up with is: {self.weights}")
self.weights_old = self.weights
self.beta = self.weights
def predict(self, X):
X = self.patek(X)
innerProd = X @ self.beta
y_hat = 1 * (innerProd > 0)
return y_hat
def score(self,X,y):
y = y.reshape(-1)
mypredict = self.predict(X)
mypredict = mypredict.reshape(-1)
myscore = 1 * (mypredict == y)
return myscore.mean()
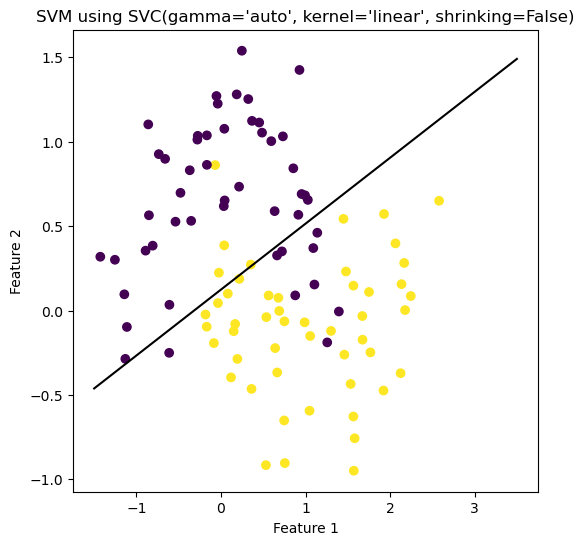
def bare_bone_plot(self, X: np.array, y: np.array, size_1: int, size_2: int) -> None:
plt.rcParams["figure.figsize"] = (size_1,size_2)
mypredict = self.predict(X)
# score = (mypredict == y).mean()
print(f"the weight beta is: {self.beta}")
a_0 = self.beta[0][0]
a_1 = self.beta[1][0]
a_2 = self.beta[2][0]
fig = plt.scatter(X[:,0], X[:,1], c = y)
xlab = plt.xlabel("Feature 1")
ylab = plt.ylabel("Feature 2")
f1 = np.linspace(-7.5, 7.5, 501)
p = plt.plot(f1, -(a_2/a_1) - (a_0/a_1)*f1, color = "black")
# title = plt.gca().set_title(f"score is: {round(score,3)}")
title = plt.gca().set_title("our regression")
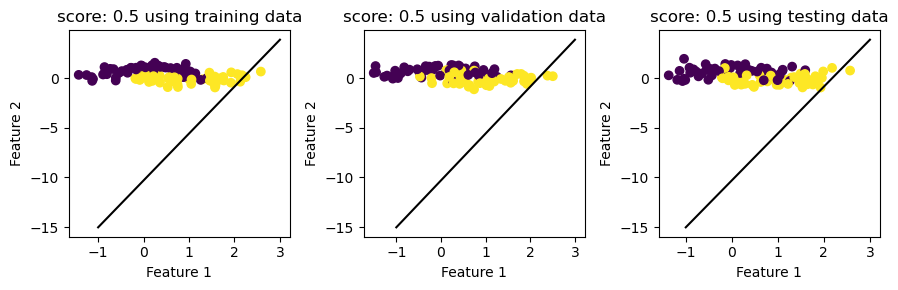
def helper_plot(self, X, y, subplot, label):
'''
Helper method for big_plot
'''
score = self.score(X,y)
a_0 = self.beta[0][0]
a_1 = self.beta[1][0]
a_2 = self.beta[2][0]
fig = subplot.scatter(X[:,0], X[:,1], c = y)
subplot.set(xlabel="Feature 1", ylabel="Feature 2", title=f"score: {round(score, 3)} using {label} data")
# the line
f1 = np.linspace(-1, 3, 501)
# p = subplot.plot(f1, -(a_2/a_1) - (a_0/a_1)*f1, color = "black")
p = subplot.plot(f1, +(a_2/a_1) - (a_0/a_1)*f1, color = "black")
def big_plot(self, X_train, y_train, X_validate, y_validate, X_test, y_test, size_1, size_2):
plt.rcParams["figure.figsize"] = (size_1,size_2)
fig, axarr = plt.subplots(1,3)
self.helper_plot(X_train, y_train, axarr[0], "training")
self.helper_plot(X_validate, y_validate, axarr[1], "validation")
self.helper_plot(X_test, y_test, axarr[2], "testing")
plt.tight_layout()